Transformer Models
Transformer are model architectures that have proven effective across range of domains such as Natural Language Processing and Computer Vision.
How Transformers work
To reduce sequential computation, many models use CNNs as building blocks., computing hidden representations in parallel for all input and output positions. However, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between the positions, making it difficult to learn dependencies between distant positions.
*The transformer reduces this to a constant number of operations, at the cost of reduced effective resolution due to averaging attention-weighted positions. This effect is counteracted with multi-head attention.*
The Transformer model relies entirely on self-attention (or intra-attention) to compute representations of its input and output without using sequence-aligned RNNs or convolution.
Making Transformer Models Efficient
The traditional Transformer model has memory and computational complexities that are quadratic with the input sequence length (\(O(N^2)\)). This limits the utility of Transformer models, since their main benefit is the ability to learn alignments across long sequences.
Efficient transformer models attempt to alleviate the cost of computing the attention matrix, either by approximating the matrix, or by introducing sparsity. NO_ITEM_DATA:tayEfficientTransformersSurvey2020 provides a good overview of these efficient Transformer models. The key summary table in the paper is reproduced below.
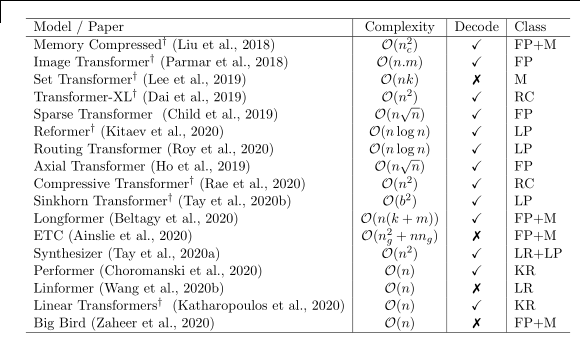
Figure 1: Summary of Efficient Transformer Models
Transformer Architectures
BART
BART is a denoising auto-encoder for pretraining sequence-to-sequence models. BART is trained by:
- corrupting text with an arbitrary noising function
- learning a model to reconstruct the original text
It generalizes BERT and GPT. One key advantage of BART is that the noising function can be arbitrarily selected. For example, they introduce an in-filling scheme replacing arbitrary lengths of text with a single mask token. This generalizes the original word masking and next sentence prediction objectives.
BART is trained by corrupting documents and then optimizing a reconstruction loss - the cross-entropy between the decoder’s output and the original document.
BART can then be fine-tuned for downstream applications:
- sequence classification
- the same input is fed into the encoder and decoder, and the final decoder token and hidden state is fed into a new multi-class linear classifier.
- token classification
- feed the complete document into the encoder and decoder, and use the top hidden state of the decoder as a representation for each word.
- sequence generation
- input sequence is given to the encoder, and the decoder generates auto-regressively.
<biblio.bib>