Spark
What is Apache Spark?
A cluster computing platform designed to be fast and general-purpose. It extends the MapReduce to support more types of computations, and covers a wide range of workloads that previously required separate distributed systems.
Spark is a computational engine that is responsible for scheduling, distributing and monitoring applications consisting of many computational tasks across many worker machines.
The Spark Stack
- Spark Core
- contains basic functionality, including memory management, scheduling, fault recovery and interacting with storage systems. It contains the API for =RDD=s, which represent a collection of items distributed across many nodes that can be manipulated in parallel.
- Spark SQL
- allows querying of data via SQL, and supports many sources of data.
- Spark Streaming
- Provides support for processing live streams of data.
- MLLib
- Contains basic ML functionality, such as classification and regression.
- GraphX
- Library for manipulating graphs, and contains common graph algorithms like PageRank.
- Cluster Managers
- Library that enables auto-scaling via cluster managers such as Hadoop YARN, Apache Mesos, and its own Standalone Scheduler.
For Data Scientists, Spark’s builtin libraries help them visualize results of queries in the least amount of time. For Data Processing, Spark allows Software Engineers to build distributed applications, while hiding the complexity of distributed systems programming and fault tolerance.
While Spark supports all files stored in the Hahoop distributed filesystem (HDFS), it does not require Hadoop.
Getting Started
Enter the shell with spark-shell, or pyspark.
lines = sc.textFile("README.md")
lines.count()
lines.first()
Core Spark Concepts
Every Spark application consists of a driver program that launches
various parallel operations on a cluster. The driver program contains
the application’s main function and defines distributed datasets on
the cluster.
Driver programs access Spark thorugh a SparkContext object, which
represents a connection to a computing cluster.
Once we have a SparkContext, we use it to create RDDs. Driver programs typically manage a number of nodes called executors. A lot of Spark’s API revolves around passing functions to its operators to run them on the cluster.
lines = sc.textFile("README.md")
lines.filter(lambda line: "Machine" in line)
Running a Python script on Spark
bin/spark-submit includes the Spark dependencies, setting up the
environment for Spark’s Python API to function. To run a python
script, simply run spark-submit script.py.
After linking an application to Spark, we need to create a SparkContext.
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My app")
sc = SparkContext(conf=conf)
Programming with RDDs
An RDD is a distributed collection of elements. All work is expressed as either creating new RDDs, transforming existing RDDs or calling operations on RDDs to compute a result.
RDDs are created by: (1) loading an external dataset, or (2) creating a collection of objects in the driver program.
Spark’s RDDs are by default recomputed every time an action is run. To
reuse an RDD in multiple actions, we can use rdd.persist. In
practice, persist() is often used to load a subset of data into
memory to be queried repeatedly.
lines = sc.parallelize(["pandas", "i like pandas"])
RDD Operations
RDDs support transformations and actions. Transformations are
operations on RDDs that return a new RDD (e.g. map and filter).
Actions are operations that return a result to the driver program, or
write it to storage,and kick off a computation.
errorsRDD = inputRDD.filter(lambda x: "error" in x)
warningsRDD = inputRDD.filter(lambda x: "warning" in x)
badLinesRDD = errorsRDD.union(warningsRDD)
Spark keeps track of RDD dependencies from various transformations in a lineage graph, that way if a RDD is lost, it can be recreated from its dependencies.
Transformations on RDDs are lazily evaluated, so Spark will not execute until an action is seen.
When passing a function that is a member of an object, or contains references to fields in an object, Spark sends the entire object to worker nodes, which can be larger than the information you need. This can also cause the program to fail, if the class contains objects that Python cannot pickle.
Basic Transformations:
map(),flatMap()- pseudo-set operations:
distinct(),union(),intersection(),subtract() cartesian()
Actions:
reduce(lambda x, y: f(x,y))fold(zero)(fn)is reduce, but takes an additional zeroth-value parameter=take(n)=,=top(n)=,takeOrdered(n)(ordering),takeSample(withReplacement, num, [seed])aggregate(zero)(seqOp, combOp)is similar reduce, but used to return a different typeforeach(fn)
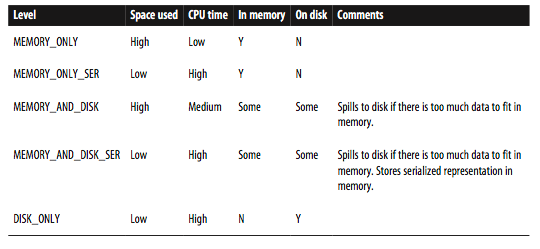
Persistence
Different level of persistence helps with making Spark jobs faster. If a node with persisted data goes down, Spark will recreate the RDD from the lineage graph.
Working with Key/Value Pairs
Spark provides special operations on RDDs with KV pairs, called pair RDDs.
For Python and Scala, the RDD needs to be composed of tuples:
pairs = lines.map(lambda x: (x.split(" ")[0], x))
val pairs = lines.map(x => (x.split(" ")(0), x))
Java does not have a built-in tuple type, so it uses the
scala.Tuple2 class.
Transformations on Pair RDDs
| Function | Purpose |
|---|---|
| reduceByKey(func) | Combines values with the same key |
| groupByKey() | Group values with the same key |
| combineByKey(a,b,c,d) | Combine values with the same key using a different result type |
| mapValues(func) | Apply a function to each value of a pair RDD without changing the key |
| flatMapValues(func) | Apply a function that returns an iterator to each value of a pair RDD. |
| keys() | Returns an RDD for just the keys. |
| values() | Returns an RDD of just the values |
| sortByKey() | Returns an RDD sorted by the key. |
Set transformations:
| Function | Purpose |
|---|---|
| subtractByKey | Remove elements with a key present in the other RDD. |
| join | Perform an inner join between the 2 RDDs |
| rightOuterJoin | Performs a join between 2 RDDs where the key must be present in the first RDD. |
| leftOuterJoin | Perform a join between 2 RDDs where the key must be in the other RDD. |
| cogroup | Group data from both RDDs sharing the same key. |
Actions:
| Function | Purpose |
|---|---|
| countByKey() | Count the number of elements for each key. |
| collectAsMap() | Collect the result as a map to provide easy lookup |
| lookup(key) | Return all values associated with the provided key. |
Data Partitioning
Spark programs can choose to control their RDDs’ partition to reduce communication. Sparks’s partitioning is available on all RDDs of key/value pairs, and cause the system to group elements based on a function of each key.
We use partitionBy() to return a new RDD that partitions the Spark
frame efficiently. Below are the operations that benefit from
partitioning:
- cogroup
- groupWith
- join
- leftOuterJoin
- rightOuterJoin
- groupByKey
- reduceByKey
- combineByKey
- lookup
Implementing a custom partitioner in Python is relatively simple:
import urlparse
def hash_domain(url):
return hash(urlparse.urlparse(url).netloc)
rdd.partitionBy(20, hash_domain)
The hash function will be compared by identity to that of other RDDs, so a global function object needs to be passed, rather than creating a new lambda.
Loading and Saving Your Data
For data stored in a local or distributed filesystem such as NFS, HDFS, or S3, Spark can access a variety of file formats including text, JSON, SequenceFiles and protocol buffers. Spark also provides structured data sources through SparkSQL, and allows connections to databases like Cassandra, HBase, Elasticsearch and JDBC databases.
SequenceFiles are a popular Hadoop format composed of flat files with key/value pairs. They have sync markers that allow Spark to seek to a point in the file and then resynchronize with the record boundaries, allowing Spark to efficiently read them in parallel from multiple nodes.
data = sc.sequenceFile(inFile, # input file
"org.apache.hadoop.io.Text", # key Class
"org.apache.hadoop.io.IntWritable", # value Class
10 # min partitions
)
data = sc.parallelize((("Panda", 3), ("Kay", 6)))
data.saveAsSequenceFile(outputFile)
SparkSQL
SparkSQL can load any table supported by Apache Hive.
from pyspark.sql import HiveContext
hiveCtx = HiveContext(sc)
rows = hiveCtx.sql("SELECT name, age FROM users")
firstRow = rows.first()
print firstRow.name
It even supports loading JSON files, if the JSON data has a consistent schema cross records.
# {"user": {"name": "Holden", "location": "SF"}, "text": "Nice"}
tweets = hiveCtx.jsonFile("tweets.json")
tweets.registerTempTable("tweets")
results = hiveCtx.sql("SELECT user.name, text FROM tweets")
Advanced Spark Programming
In this section, we look at some techniques that were not previously covered, in particular shared variables: accumulators to aggregate information and broadcast variables to efficiently distribute large values.
{
"address": "address here",
"band": "40m",
"callsign": "KK6JLK",
"city": "SUNNYVALE",
"contactlat": "37.384733",
"contactlong": "-122.032164",
"county": "Santa Clara",
"dxcc": "291",
"fullname": "MATTHEW McPherrin",
"id": 57779,
"mode": "FM",
"mylat": "37.751952821",
"mylong": "-122.4208688735"
}
Accumulators
When we normally pass functions to Spark, they can use variables defined outside of them in the Spark program, but updates to these variables are not progagated to the driver. Spark’s shared variables relax this restriction for two common typess of communication patterns: aggregation of results and broadcasts.
file = sc.textFile(inputFile)
blankLines = sc.accumulator(0)
def extractCallSigns(line):
global blankLines # Make the global variable accessible
if (line == ""):
blankLines += 1
return line.split(" ")
callSigns = file.flatMap(extractCallSigns)
Tasks on worker nodes cannot access the accumulator’s value. This allows accumulators to be implemented efficiently without having to communicate every update.
For accumulators used in actions, Spark applies each task’s update to
each accumulator only once. Thus, for a reliable absolute value
counter, the accumulator should be in an action such as foreach(). For
accumulators used in RDD tarnsformations instead of actions, this
guarantee does not exist.