Multi-modal Translation
Multi-modal translation is a sub-challenge in multi-modal machine learning, involving the translation of one modality to another. Some applications of multi-modal translation involve speech synthesis, video description, and cross-modal retrieval. Image and video captioning is a particularly popular problem, with large multi-modal datasets available.
Multi-modal translation can be categorized into example-based, and generative approaches (Baltrušaitis, Ahuja, and Morency, n.d.).
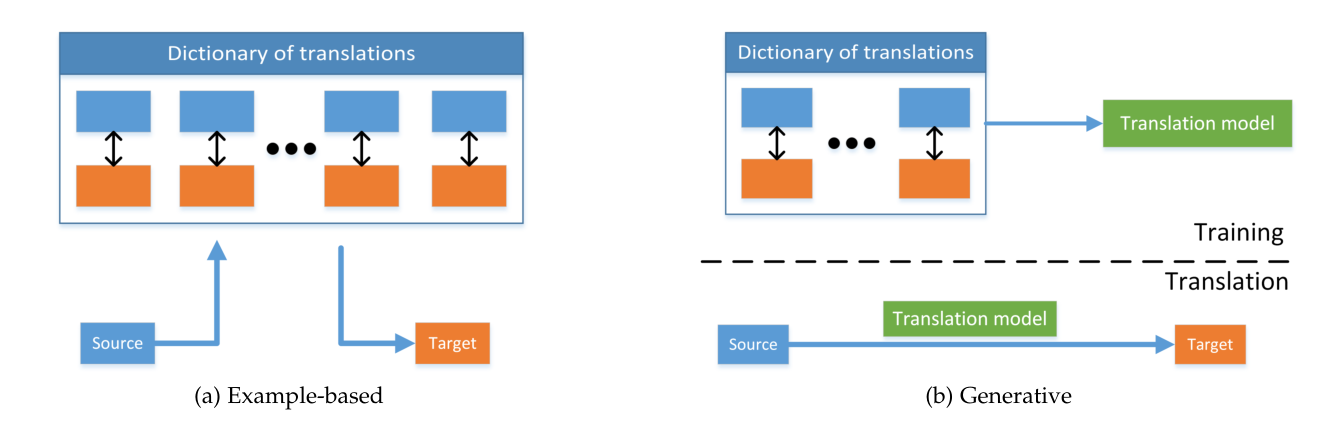
Figure 1: Example-based and generative multi-modal translation
Example-based
Example-based models use a dictionary to translate between modalities. These algorithms are restricted by their training data.
Retrieval-based models rely on finding the closest sample in the dictionary, and using that as the translated result. The similarity metric can be computed in some semantic space. Retrieval approaches in semantic space tend to perform better than in the unimodal space, as this space is optimized for retrieval. They also allow for bi-directional translation. However, these approaches require either manual construction or learning of this semantic space, which requires large datasets.
Combination-based models extend retrieval-based models, by combining multiple examples from the dictionary to construct a better translation. These approaches are motivated by the fact that sentence descriptions of images often share a common and simple structure that could be exploited. These rules are often hand-crafted, or based on heuristics.
Example-based approaches are often large and have slow inference speeds, because of the large dictionaries.
Generative
The generative approach constructs a model that is able to produce a translation. This requires the ability to both understand the source modlity, as well as generate the target squence or signal. Thes methods are also difficult to evaluate.
Grammar-based models rely on a pre-defined grammar for generating a particular modality. They detect high level concepts from the source modality, such as objects in images. These detections are incorporated together with a generation procedure, such as a rule-based sentence generation. These models are more likely to generate syntactically and logically correct target instances, due to the predefined templates and restrictive grammars, but limits the creative output of the model.
Encoder-decoder models use end-to-end trained neural networks, first encoding the source modality into a vectorial representation, and later decoding it to generate the target modality.
Continuous generation models are intended for sequence translation, and produce outputs at every timestep in an online manner. These models are often seen in text-to-speech, speech-to-text, or video-to-text. Encoder-decoder approaches are common used. Continuous generation models have to tackle the additional difficulty of temporal consistency between modalities.
Bibliography
Baltrušaitis, Tadas, Chaitanya Ahuja, and Louis-Philippe Morency. n.d. “Multimodal Machine Learning: A Survey and Taxonomy.” http://arxiv.org/abs/1705.09406v2.