Interval Estimation in Bayesian Statistics
Suppose instead of point estimation, we’d like to identify a region that is likely to contain the true value of parameter \(\theta\). In Bayesian Inference, this region is called the credible set, or the Bayesian confidence interval.
A \(100(1-\alpha)%\) credible set for \(\theta\) is subset \(\mathcal{C}\) of \(\Theta\) such that:
\begin{equation} P(\theta \in \mathcal{C} | y)=\int_{\mathcal{C}} p(\theta | y) \mathrm{d} \theta \geq 1-\alpha \end{equation}
Interpreting credible sets is different in Bayesian statistics, compared to frequentist confidence intervals.
In Bayesian statistics, the unknown parameters \(\theta\) is regarded as a random variable, and the interval is fixed once data is observed. That is, we can make direct probabilistic statements like:
The probability that \(\theta\) lies in \(\mathcal{C}\) given observed data \(y\) is \((1-\alpha)\).
In frequentist statistics, \(Y\) is regarded as random, giving rise to a random interval which has probability \((1-\alpha)\) of containing the fixed but unknown \(\theta\). The corresponding statement is:
If we could recompute \(\mathcal{C}\) for a large number of datasets collected the same way, then about \(100(1-\alpha)%\) of them will contain the true value of \(\theta\)
Another way to view this is that frequentist and Bayesian notions of coverage describe pre- and post-experimental coverage respectively. Researchers have shown that Bayesian credible sets constructed via some methods will also have almost the correct frequentist coverage.
Quantile/equal-tails intervals
We find two numbers \(\theta_{\alpha / 2}<\theta_{1-\alpha / 2}\), such that:
\begin{equation} \mathrm{P}\left(\theta<\theta_{\alpha / 2} | y\right)=\alpha / 2 \quad \text { and } \quad \mathrm{P}\left(\theta>\theta_{1-\alpha / 2} | y\right)=\alpha / 2 \end{equation}
The \(100(1-\alpha)%\) quantile-based CI is \(\left[\theta_{\alpha / 2}, \theta_{1-\alpha / 2}\right]\).
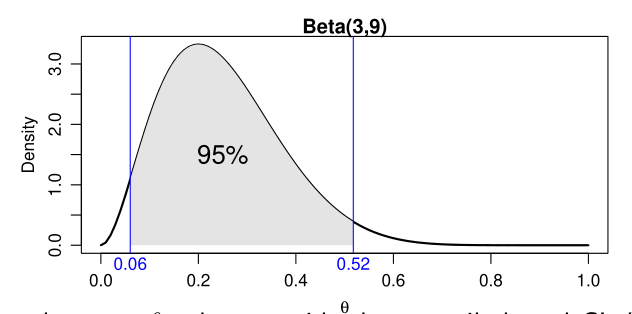
Figure 1: Quantile-based 95% CI for Beta(3,9)
Highest Posterior Density (HPD) region
The HPD credible set is defined as the set:
\begin{equation} \mathcal{C}=\{\theta \in \Theta: p(\theta | y) \geq k(\alpha)\} \end{equation}
where \(k(\alpha)\) is the largest constant satisfying:
\begin{equation} P(\theta \in \mathcal{C} | y) \geq 1-\alpha \end{equation}
All points in a HPD region have higher posterior density than points outside the region.
To visualize this, imagine drawing a horizontal line across the graph at the mode of the posterior distribution, and the pushing it down until the corresponding values on the \(\theta\) axis contains the appropriate probability.
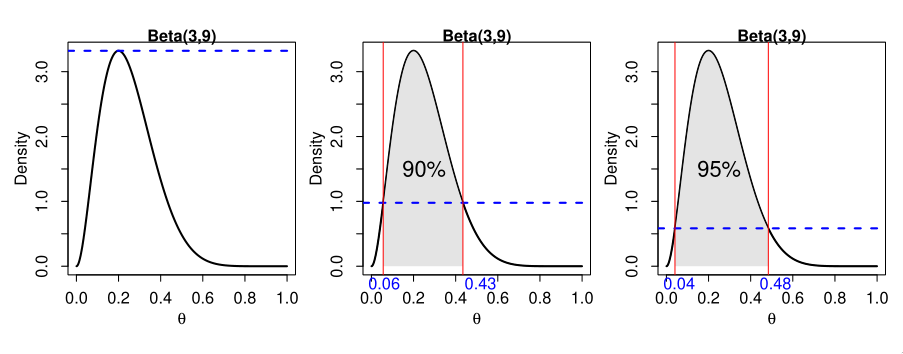
Figure 2: 90% and 95% HPD regions on a Beta(3,9) distribution
Computing HPD requires numerical methods. HPD might not be an interval
if the distribution is multimodal. Some packages like coda assumes
that the distribution is not severely multimodal.
Generally, the quantile-based CI will be equal to the HPD region if the posterior is symmetric and uni-modal, but wider otherwise. For unimodal posterior densities, the HPD interval has the shortest length for the same level of coverage.