Attention (ML)
In typical encoder-decoder architectectures, the full sentence is compressed into an output vector by the encoder, which is fed into the decoder to produce the desired output. The decoder produces outputs until a special token is received.
It is often unreasonable to expect that the encoder can fully compress the source sentence into a single vector. Attention mechanisms allow the decoder to attend to different parts of the source sentence at each step of the output generation.
The decoder output word \(y_t\) now depends on a weighted combination of all the input states, not just the last state. These attention weights \(a_{t,i}\) are often normalized to sum to 1.
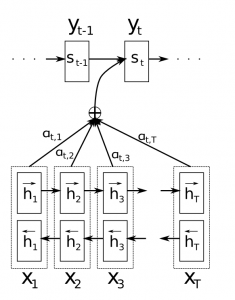
Attention allows us to visualize what the model is doing, by inspeting the attention weight matrix.